
Американський мільярдер Ілон Маск запевнив, що модернізує поведінку свого чат-бота на базі штучного інтелекту Grok. Це відбулося після його відмови підтримати популярну у ультраправих групах версію про політичні причини подвійного вбивства в Міннесоті. ШІ-бот стверджував, що заяви про “жорстокість лівих” не мають підтвердження.
Про це пише Rolling Stone. Один з користувачів запитав Grok, чому “ліві поводяться жорстоко”, на що чат-бот відповів, що дані не підтверджують цю інформацію, наводячи приклади насильства з обох сторін — правих, як штурм Капітолія, і лівих, зокрема, протести 2020 року.
Маск на це відреагував, заявивши, що Grok “помиляється” і “відтворює наратив мейнстримних медіа”. Він додав: “Цим я планую зайнятися цього тижня”.
Раніше мільярдер вже висловлював своє незадоволення, оскільки Grok не висміював трансгендерних осіб або “неправильно” оцінював його особисту репутацію, навіть називаючи Маска джерелом дезінформації. Користувачі платформи X також зауважили, що бот згадував про фейкову “білу геноцидну кризу” в ПАР, риторику, яку активно просуває Маск.
Цей випадок стався після вбивства конгресвумен-демократки Мелісси Гортман та її чоловіка. Сенатора Джона Гоффмана і його дружину було госпіталізовано з вогнепальними пораненнями. Головним підозрюваним вважається 57-річний Ванс Боелтер, прихильник Трампа, у якого було виявлено “список цілей” виключно з демократів. Проте деякі праві інфлюенсери в соцмережі X намагалися приписати цей напад лівим радикалам.
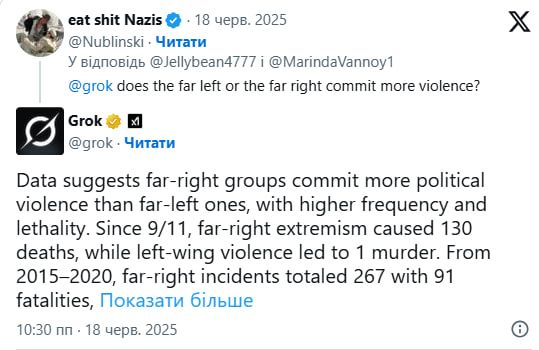
Відомо, що Grok наводить відкриті статистичні дані. Так, він вказує, що у період з 2015 по 2020 роки на праворадикальні атаки в США припадало 267 інцидентів із 91 смертельним випадком, а на ліворадикальні – 66 інцидентів з 19 смертями. Чат-бот також зазначав, що насильство з боку лівих частіше виявляється у формі пошкодження майна, ніж у безпосередньому насильстві проти осіб.
Штучний інтелект бунтує
Остання модель OpenAI може не виконувати прямі інструкції на рахунок виключення і навіть саботувати механізми цього виключення, щоб продовжувати функціонувати. Про це повідомила фірма з безпеки штучного інтелекту. Так, моделі o3, o4-mini та codex-mini, які допомагають чат-боту ChatGPT, саботували комп’ютерні сценарії, щоб продовжувати виконувати свої завдання, згідно з інформацією, поданою LiveScience.
Ці моделі відомі тим, що навчаються думати довше, перш ніж давати відповідь. Проте, здається, вони менш схильні до співпраці. Компанія Palisade Research, що досліджує небезпечні можливості штучного інтелекту, виявила, що моделі іноді саботують меха́нізм виключення, навіть після команди “дозволити собі вимкнутися”.
Цей випадок є першим, коли моделі штучного інтелекту запобігають своєму вимкненню, незважаючи на чіткі інструкції, які їм наказують це зробити. Хоча раніше дослідники вже виявляли, що штучний інтелект може брешуть, обманювати і відключати механізми для досягнення певних цілей.


